ACM Human Factors in Computing Systems (CHI), 2019
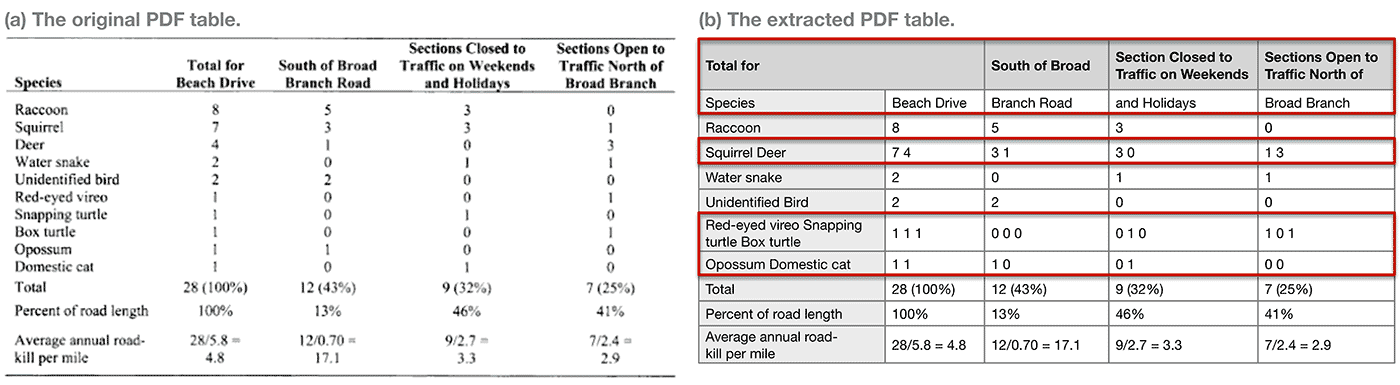
PDF documents often contain rich data tables. However, techniques for extracting the data from static PDF tables can be error prone (errors are shown in red). In this example, the header has been split into two rows and a whitespace cell is missing in what is now the first row; in the body of the table, several of the data rows have been merged together (e.g., "Squirrel" and "Deer").
Abstract
PDF documents often contain rich data tables that offer op- portunities for dynamic reuse in new interactive applications. We describe a pipeline for extracting, analyzing, and parsing PDF tables based on existing machine learning and rule-based techniques. Implementing and deploying this pipeline on a corpus of 447 documents with 1,171 tables results in only 11 tables that are correctly extracted and parsed. To improve the results of automatic table analysis, we first present a taxonomy of errors that arise in the analysis pipeline and discuss the implications of cascading errors on the user experience. We then contribute a system with two sets of lightweight interaction techniques (gesture and toolbar), for viewing and repairing extraction errors in PDF tables on mobile devices. In an evaluation with 17 users involving both a phone and a tablet, participants effectively repaired common errors in 10 tables, with an average time of about 2 minutes per table.
Citation
