ACM Human Factors in Computing Systems (CHI), 2020

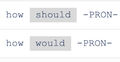
Structural templates abstract textual queries by replacing certain tokens with their linguistic features, so the queries with shared templates can be examined from different angles. For example, in q1, by replacing "Bill Gates" with its named entity "PERSON" (t2), we can find celebrities users care about when asking "how rich" questions. Or, we can collect and explore queries on "Bill Gates" if we abstract "rich" to its part-of-speech tag, adjective (t4). Such templates are useful for both dataset exploration (e.g., recognize "how rich is PERSON" is a common question pattern in a query dataset) and model error analysis (e.g., distinguish a model’s ability in retrieving information about "rich" and recognizing "Bill Gates").
Abstract
Analyzing queries from search engines and intelligent assistants is difficult. A key challenge is organizing queries into interpretable, context-preserving, representative, and flexible groups. We present structural templates, abstract queries that replace tokens with their linguistic feature forms, as a query grouping method. The templates allow analysts to create query groups with structural similarity at different granularities. We introduce Tempura, an interactive tool that lets analysts explore a query dataset with structural templates. Tempura summarizes a query dataset by selecting a representative subset of templates to show the query distribution. The tool also helps analysts navigate the template space by suggesting related templates likely to yield further explorations. Our user study shows that Tempura helps analysts examine the distribution of a query dataset, find labeling errors, and discover model error patterns and outliers.
Citation