IEEE Trans. Visualization & Comp. Graphics (Proc. VIS), 2022
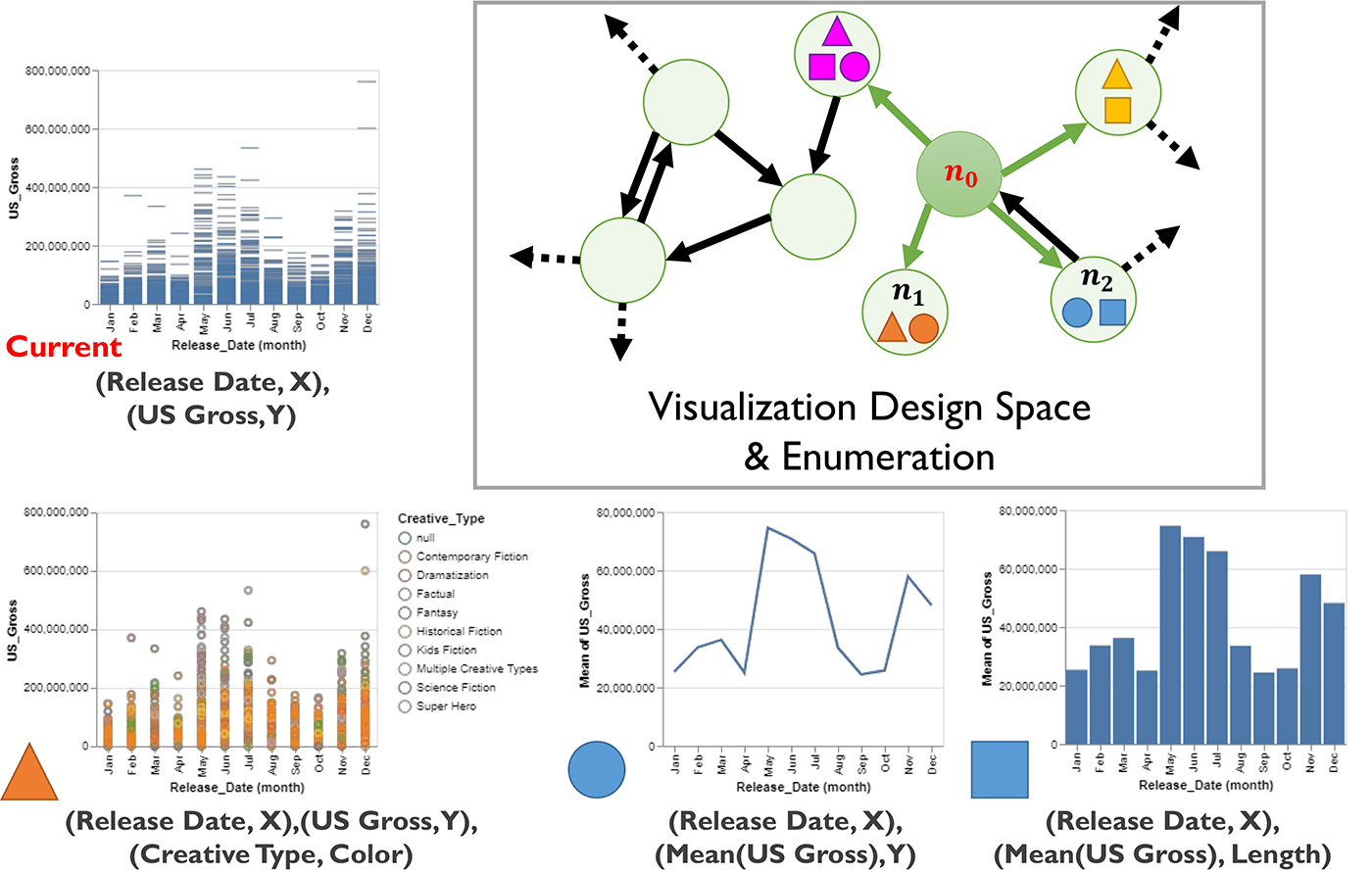
We present a new framework for evaluating visualization recommendation systems, based on the central process connecting most if not all algorithms that power these types of systems: to generate the "best" recommendations, an algorithm must be able to enumerate the space of possible visualization designs and rank this design space, often by approximating and comparing the utility of candidate visualizations. The visualization design space can be represented as a graph, where nodes are visualization designs and edges connect designs that differ by a single encoding or data transformation. The enumeration step of recommendation algorithms can be represented as a series of paths through the graph from a starting node (e.g., the user's current visualization) to one or more target nodes. Here, movies data is used to illustrate possible candidate visualizations within a visualization design space, and how this space can be enumerated by a visualization recommendation algorithm. In this case, the algorithm's enumeration strategy is to recommend all visualization designs that differ by at most a single encoding/transformation (represented by the green arrows).
Abstract
Although we have seen a proliferation of algorithms for recommending visualizations, these algorithms are rarely compared with one another, making it difficult to ascertain which algorithm is best for a given visual analysis scenario. Though several formal frameworks have been proposed in response, we believe this issue persists because visualization recommendation algorithms are inadequately specified from an evaluation perspective. In this paper, we propose an evaluation-focused framework to contextualize and compare a broad range of visualization recommendation algorithms. We present the structure of our framework, where algorithms are specified using three components: (1) a graph representing the full space of possible visualization designs, (2) the method used to traverse the graph for potential candidates for recommendation, and (3) an oracle used to rank candidate designs. To demonstrate how our framework guides the formal comparison of algorithmic performance, we not only theoretically compare five existing representative recommendation algorithms, but also empirically compare four new algorithms generated based on our findings from the theoretical
comparison. Our results show that these algorithms behave similarly in terms of user performance, highlighting the need for more rigorous formal comparisons of recommendation algorithms to further clarify their benefits in various analysis scenarios.
Materials
Citation